Der k-nächste-Nachbarn-Algorithmus mit Tabellenkalkulation
Zur Visualisierung und Simulation des maschinellen Lernprozesses am Beispiel des k-nächste-Nachbarn-Algorithmus wurden Tabellenkalkulationsmappen (speziell für Microsoft Excel und LibreOffice Calc) erstellt, welche es ermöglichen, einzelne Schritte im maschinellen Lernprozess (Klassifikation, Training, Bestimmung des Hyperparameters k, Testen, ...) zu simulieren und selbst auszuprobieren. Diese Mappen stehen in zwei Versionen mit unterschiedlichen Anwendungskontexten (Klassifikation von T-Shirtgrößen und Klassifikation von Irispflanzenarten) zur Verfügung.
Klassifikation mit dem k-nächste-Nachbarn-Algorithmus
Die Tabellenkalkulationsmappen sind jeweils in Tabellen unterteilt, welche jeweils einen Aspekt des maschinellen Lernprozesses des k-nächste-Nachbarn-Algorithmus (kNN-Algorithmus) veranschaulichen.
Erklärung gemäß Leitfaden zur Nutzung von Screenshots von Microsoft-Produkten: Used with permission from Microsoft.
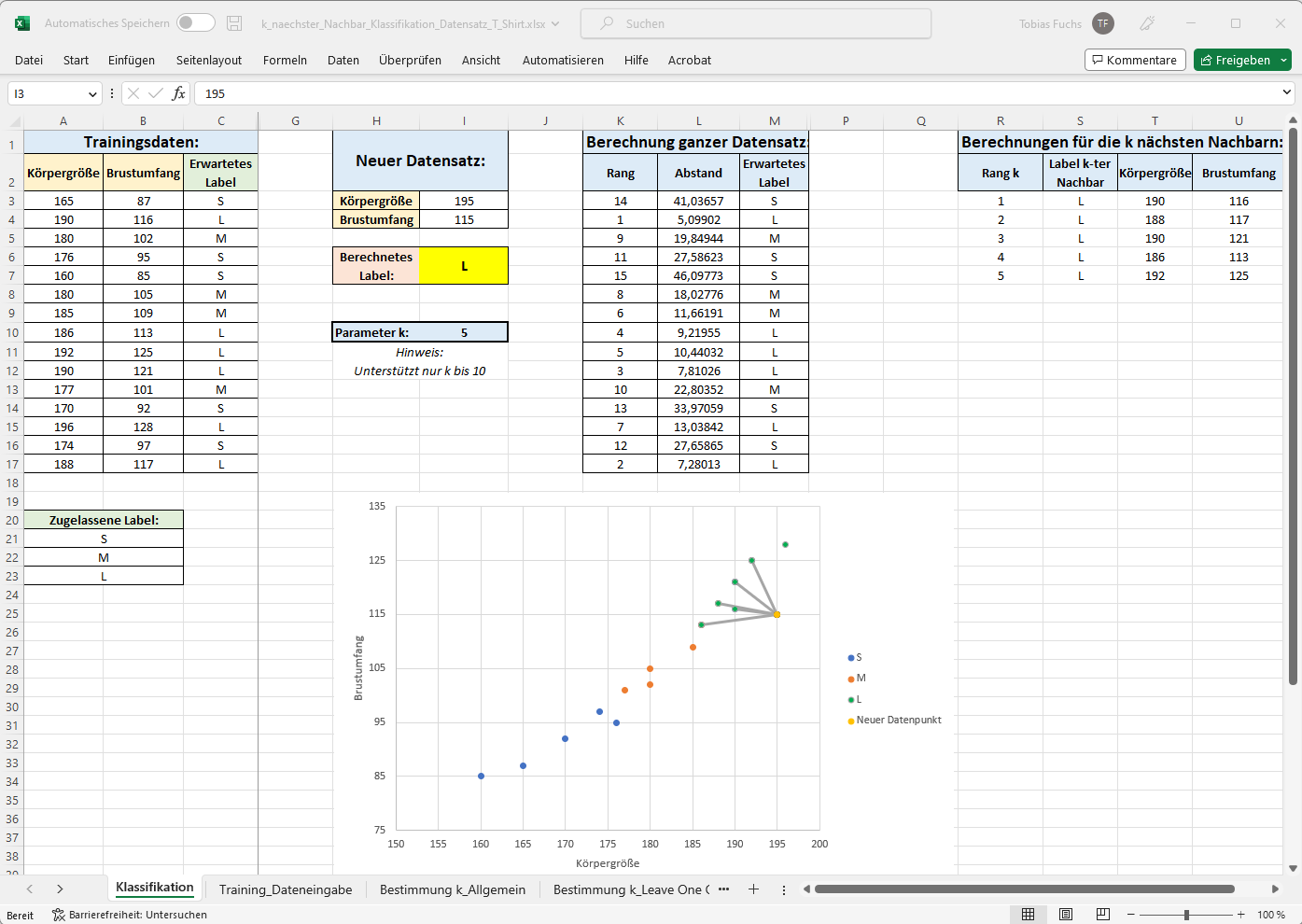
- Klassifikation eines neuen, einzugebenden Datenpunkts mit Hilfe des
kNN-Algorithmus
Der kNN-Algorithmus eignet sich zur Klassifikation von Datenpunkten, d.h. die Einordnung eines Datenpunkts anhand seiner Merkmale in eine vorhandene Klasse. Mit Hilfe der TK-Mappe kann dies in der Tabelle Klassifikation (Reiterauswahl im unteren Bereich der Mappe) simuliert werden. Dafür muss lediglich ein für den gewählten Kontext passender Datenpunkt im Bereich Neuer Datenpunkt eingegeben und der Parameter k auf den gewünschten Wert gesetzt werden. In der Tabelle wird nun die mit Hilfe des kNN-Algorithmus vorhergesagte Klasse für den neuen Datenpunkt angezeigt zusammen mit einer graphischen Darstellung der k nächsten Nachbarn des Datenpunkts. - Training des kNN-Modells
Das Trainieren des Modells beim k-nächste-Nachbarn-Algorithmus ist, im Vergleich zu anderen Algorithmen maschinellen Lernens, denkbar einfach. Hier müssen nur die Trainingsdaten geladen d.h. in den vorbereiteten Bereich der Tabelle Training_Dateneingabe kopiert werden und das Training des Modells ist abgeschlossen. - Bestimmung des Hyperparameters k allgemein
Der Hyperparameter k legt fest, wie viele Nachbarn eines zu klassifizierenden Datenpunkts für die Klassifikation, d.h. die Einordnung in eine Klasse, herangezogen werden. Die Wahl des Parameters k ist also von zentraler Bedeutung für den k-nächste-Nachbarn-Algorithmus. Die Auswahl des Parameters erfolgt in der Regel nicht zufällig, sondern es werden passende Werte unter Verwendung der Validierungsdaten bestimmt.
In der Tabelle Bestimmung_k_allgemein kann das Vorgehen zur strukturierten Bestimmung des Parameters k schrittweise durchgeführt werden. Eine Erläuterung des Verfahrens sowie eine Beschreibung der einzelnen durchzuführenden Schritte in der Tabellenkalkulationsmappe finden Sie im zugehörigen Handbuch. - Bestimmung des Hyperparameters k mit Hilfe des
Leave-One-Out-Verfahrens
Wie im vorherigen Abschnitt beschrieben, werden die Validierungsdaten verwendet um geeignete Werte für den Parameter k zu finden. Nachdem dieser Parameter k gefunden wurde, sind die Validierungsdaten im Normalfall nutzlos. Es gibt aber Verfahren der Kreuzvalidierung mit deren Hilfe keine Aufteilung in Trainings- und Validierungsdaten notwendig ist und somit nach der Bestimmung des Parameters k keine Daten nutzlos werden. Ein Beispiel für ein Verfahren der Kreuzvalidierung ist das Leave One Out - Verfahren.
In der Tabelle Bestimmung_k_Leave_One_Out kann das Vorgehen zur strukturierten Bestimmung des Parameters k mit Hilfe des Leave One Out - Vefahrens schrittweise durchgeführt werden. Eine Erläuterung des Verfahrens sowie eine Beschreibung der einzelnen durchzuführenden Schritte in der Tabellenkalkulationsmappe finden Sie im zugehörigen Handbuch. - Testen des trainierten Modells und Darstellung der Ergebnisse in Form
einer Konfusionsmatrix
Das Testen stellt neben dem Training den zweiten großen Bestandteil des maschinellen Lernprozesses dar. In der Tabelle Testen_Konfusionsmatrix kann schrittweise die Konfusionsmatrix für eine Menge an Testdaten gefüllt werden. Zusätzlich wird automatisch das Gütemaß Genauigkeit berechnet, welches eine Aussage über die Vorhersagequalität des trainierten Modells ermöglicht.
Eine Erläuterung des Verfahrens sowie eine Beschreibung der einzelnen durchzuführenden Schritte in der Tabellenkalkulationsmappe finden Sie im zugehörigen Handbuch.
Weitere Anwendung: Regression
Des Weiteren wurde eine weitere Tabellenkalkulationsmappe erstellt um eine weitere Anwendung des
k-nächste-Nachbarn-Algorithmus, die Regression, zu demonstrieren. Hierfür wurde der
Anwendungskontext Vorhersage eines Hauspreises in Abhängigkeit des Merkmals Fläche in m²
gewählt.
Diese Tabellenkalkulationsmappe können Sie gemeinsam mit den Dateien zur Anwendung
Klassifikation im Bereich
Downloads herunterladen.